

Fields of Computational Biology
Computational biology is defined as the use of data analysis, mathematical modeling and computational simulations to understand biological systems and relationships... but that description is daunting to say the least. Here I try to break down the various fields of computational biology into brief summaries that are more approachable!
BEGINNER FRIENDLYEXPLAINER
Sohum Bhardwaj
7/7/20245 min read
Genomics
The genome is simply all the genes of an organism combined, and Genomics is the study of it. There are several reasons why studying the genome is fruitful. Geonomics can help find mutations that lead to an increased chance of certain diseases which allows for personalized treatment plans, and it can aid the creation of new drugs to patch genetic vulnerabilities. But how do we analyze the genome? The genome is first sequenced by specialized machines that read DNA strands and convert them into data. For example, AGT represents the sequence adenosine, guanine, thymine which are three of the bases that make up DNA. All the DNA is converted into this sequenced text which is known as raw data. When all this raw data is collected, it is time for computational biology to shine. Computational biologists focus on developing sophisticated algorithms to analyze the data and locate genes that are associated with certain diseases or predict how the genome will respond to certain drugs.
Landmark Achievement Spotlight: Human Genome Project
In April of 2003, the NIH finished the Human Genome Project which was an ambitious undertaking that lasted 13 years and cost a billion dollars. The fruit of their labor was the complete sequencing of the human genome which kickstarted the field of genomics.
Technologies being utilized in this field:
BLAST
The Basic Local Alignment Search Tool (BLAST) is used to find similar sequences across many different samples of genes. It alone has thousands of citations, but more advanced versions of the tool have also emerged like PSI-BLAST
Machine Learning
Machine learning techniques are crucial to creating the algorithms that analyze these gigantic datasets.
DNA Sequencing
Modern day DNA sequencing machines can process hundreds of billions of bases per day which translates to sequencing the entire human genome in just 2 days and for a thousand dollars.


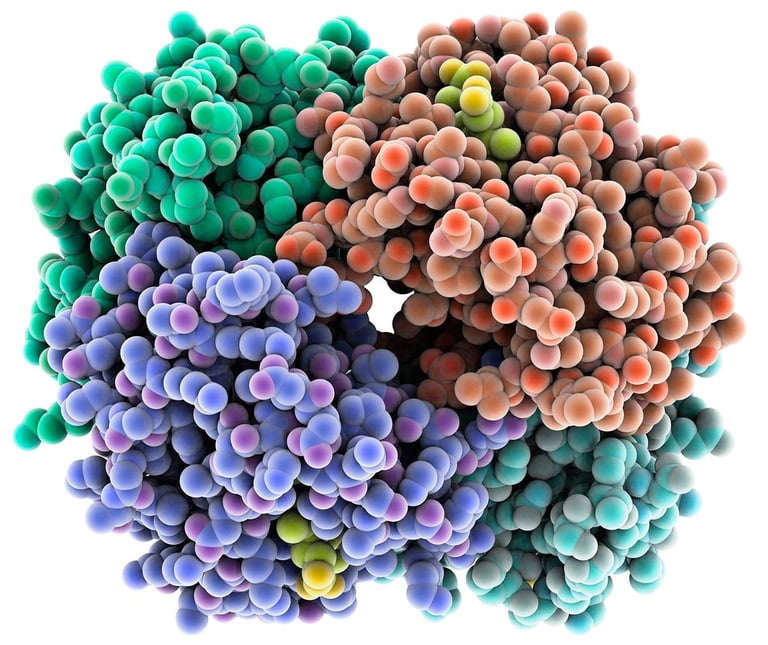
Proteomics
Proteomics is the study of the proteome of an organism or all the proteins that the organism produces (I’m sure you can see the similarity with genomics), Mass spectrometry is able to quantify and identify the proteins in a sample. This creates large amounts of data which is where computational biology shines. Computational models analyze how the regulation of proteins changes based on disease or other conditions from this data. Additionally, mass spectrometry and experimental data is often used to train PTM (post-translational modification) models which predict what changes may occur to a protein after the translation phase in protein synthesis. Computational models also examine how proteins affect other proteins (protein-protein interactions) and serve many other purposes, but at risk of droning on I’ll leave those for you to discover!
Landmark Achievement Spotlight: AlphaFold
Developed by DeepMind, AlphaFold is a deep learning algorithm that is able to reliably predict how a protein folds. It was like a bombshell on proteomics when it came out as before AlphaFold expensive and inefficient processes were used just to figure out how one protein folded. On the other hand, AlphaFold has identified over 100,000 proteins which has dramatically improved our coverage of the proteome.
Technologies being utilized in this field:
AlphaFold
The database created by AlphaFold is used by researchers studying proteins and enables researchers to move quicker and tackle questions they couldn’t have before because they have access to information that would have been otherwise labor intensive to collect.
Mass Spectrometry
Mass Spectrometry generates large datasets of proteomic data for computational models to train off of.
Phylogeny and Evolution
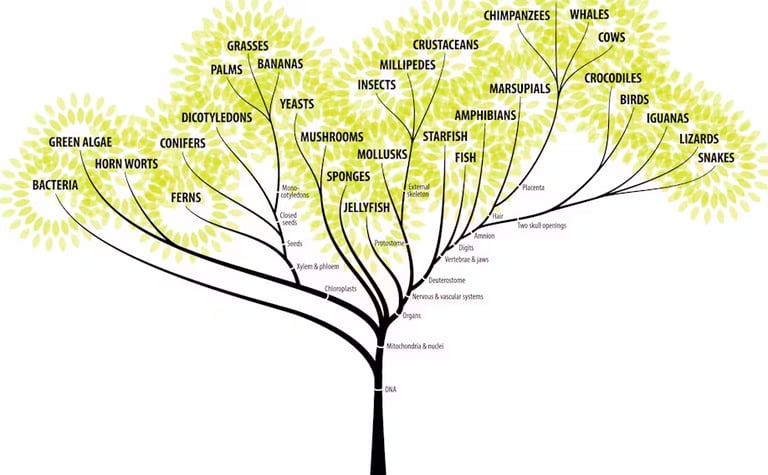
Phylogenesis is development of an organism through evolution which leads to divergence and new species being formed. Evolutionary biologists like to map Phylogenesis by using phylogenetic trees which document how species are related to one another through evolution. Enter computational biology: computational models are used to construct phylogenetic trees given a variety of different types of data such as DNA and RNA sequences. As well as proteins and molecular markers. Models have to use all of this data to construct the most accurate phylogenetic trees which is quite the challenge.
Landmark Achievement Spotlight:
Bette Korber’s study on the Evolution of HIV-1
Korber used Maximum-Likelihood, which is a type of algorithm used by computational models to create phylogenetic trees, on a very large dataset of HIV-1 strands. To do this, Korber used IBM’s roadrunner supercomputer which can process over a quadrillion calculations a second. As a result, she published a study that gave insights into the complex nature of HIV-1 and proved that computers and math could be used effectively in phylogeny.
Technologies being utilized in this field:
DNA, RNA, and Protein Sequencing
DNA, RNA, and Proteins are used as data for algorithms to create complex phylogenetic trees. Therefore, the sequencing of these biological molecules is essential to the field of evolutionary biology
Machine Learning
Maximum Likelihood and Maximum Parsimony are just two of the many different machine learning algorithms employed to create the optimal phylogenetic tree.
Metabolic Pathway Modeling
Metabolic Pathways are the processes in organisms that create metabolites (the output of metabolic pathways). These metabolic pathways often consist of hundreds of different enzymes and many different regulatory systems that work to guarantee that the right amount of metabolite is created when it is needed. Computational models take in a variety of different types of data such as metabolite concentrations, protein concentrations, and several mathematical equations in order to predict the dynamics (how it changes) of metabolic pathways. Oftentimes, metabolic pathway models can be adjusted to predict other similar things like gene regulatory networks. Overall, these types of models are quite tricky to create but very powerful in terms of their possibilities.
Landmark Achievement Spotlight:
Whole Cell Modeling (Of Mycoplasma Genitalium)
Whole cell modeling combines knowledge of all the metabolic pathways in a cell and how they interact with each other. More specifically, the whole cell model illustrates the entire life-cycle of a cell which includes the various metabolites and enzymes at work in the cell. While the whole cell model of the human cell is quite a while away, the whole cell model of Mycoplasma Genitalium shows a hopeful sign of progress in the field.
Technologies being utilized in this field:
Machine Learning, Sequencing technologies, and mass spectrometry are all used to collect data and create powerful algorithms that create the models for metabolic analysis.
Sources
Genomics:
https://sitn.hms.harvard.edu/flash/2019/the-computer-science-behind-dna-sequencing/
https://icahn.mssm.edu/research/genomics/research/computational-biology
https://scaleuplab.gatech.edu/unveiling-the-future-of-computational-biology-a-paradigm-shift-in-scientific-discovery/
https://www.genome.gov/about-genomics/fact-sheets/A-Brief-Guide-to-Genomics
Proteomics
https://deepmind.google/technologies/alphafold/
https://www.technologynetworks.com/proteomics/articles/trends-and-advancements-in-proteomics-377815
https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.0030114
Phylogeny and Evolution
https://www.mit.edu/~kardar/research/seminars/Immunology/papers/Korber.pdf
https://cgp.iiarjournals.org/content/cgp/2/5/301.full.pdf
https://link.springer.com/chapter/10.1007/978-981-33-6191-1_5
Metabolic Pathway Modeling
https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-020-03808-8#Abs1
https://chem.libretexts.org/Bookshelves/Physical_and_Theoretical_Chemistry_Textbook_Maps/Supplemental_Modules_%28Physical_and_Theoretical_Chemistry%29/Spectroscopy/Magnetic_Resonance_Spectroscopies/Nuclear_Magnetic_Resonance/Nuclear_Magnetic_Resonance_II
https://www.wholecell.org/models/